一. HBase概述
HBase(Hadoop Database)是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。HBase 本质上是一个数据模型,可以提供快速随机访问海量结构化数据。利用 Hadoop 的文件系统(HDFS)提供的容错能力。它是 Hadoop 的生态系统,使用 HBase 在 HDFS 读取消费/随机访问数据,是 Hadoop 文件系统的一部分。HBase 是一个面向列的数据库,在表中它由行排序。
Hbase的适用场景为
- 写密集型应用,每天写入量巨大,而相对读数量较小的应用,比如IM的历史消息,游戏的日志等等。
- 不需要复杂查询条件来查询数据的应用,HBase只支持基于rowkey的查询,对于HBase来说,单条记录或者小范围的查询是可以接受的,大范围的查询由于分布式的原因,可能在性能上有点影响,而对于像SQL的join等查询,HBase无法支持。
- 对性能和可靠性要求非常高的应用,由于HBase本身没有单点故障,可用性非常高。
二. HBase逻辑模型
1.表(table):
表的作用将存储在HBase的数据组织起来。
2.行健(rowkey):
行的唯一标示类似于主键; 按照字典序进行排序储存;最大长度是64KB,但是建议长度是10-100byte。
3.列族(column family):
在行中的数据都是根据列族分组;
在HBase想要使用列,必须要指定列族,列必须要归属于某一个列族;
4.列族需要在表定义的时候预先给出,而列不需要;
列族是存储,权限控制,调优的最小单元。
5.时间戳(timestamp):
时间戳是给定值的一个版本号标识,每一个值都会对应一个时间戳,时间戳是和每一个值同时写入HBase存储系统中的。在默认情况下,时间戳表示数据服务在写入数据时的系统时间。

在实际的HDFS存储中,以及存储每个字段数据所对应的完成的键值对:
{row key,column family,column name,timestamp}->value
如上图key3行Address字段下t2时间戳下的数值Shanghai,存储的完整键值对是:
{key3,PersonalInfo,Address,t2}->Shanghai
也就是说Hbase真实是不存在行列的概念,只有键值对的概念。其行的概念是通过相邻的键值对的数据比较构建出来的。所以其物理上不是二维表的概念。
三. HBase物理模型
对于HBase 的物理模型包括Table的分割、Region的拆分、Region的分布,Region的构成。
Table的分割 是指Table 中的所有行都按照 rowkey 的字典序排列,Table 在行的方向上分割为多个Region,一个Region在同一时刻只能被同一个RegionServer管理,RegionServer可以管理多个Region(一对多),
Region的拆分 Region是按大小分割的,新创建的表只有一个region(数据为空),随着数据增多,region不断增大,当增大到一个阀值时,region就会拆分为两个新的region,之后会有越来越多的region。
Region 的分布 Region 是 HBase 中分布式存储和负载均衡的最小单元,不同的Region分布到不同的RegionServer上。
Region的构成 Region虽然是分布式分布式存储的最小单元,但并不是存储的最小单元,Store是存储的最小单元,Region由一个或者多个Store组成,每个Store会保存一个Column Family;每个Store又由一个MemStore或0至多个StoreFile组成;MemStore存储在内存中,StoreFile存储在HDFS中。
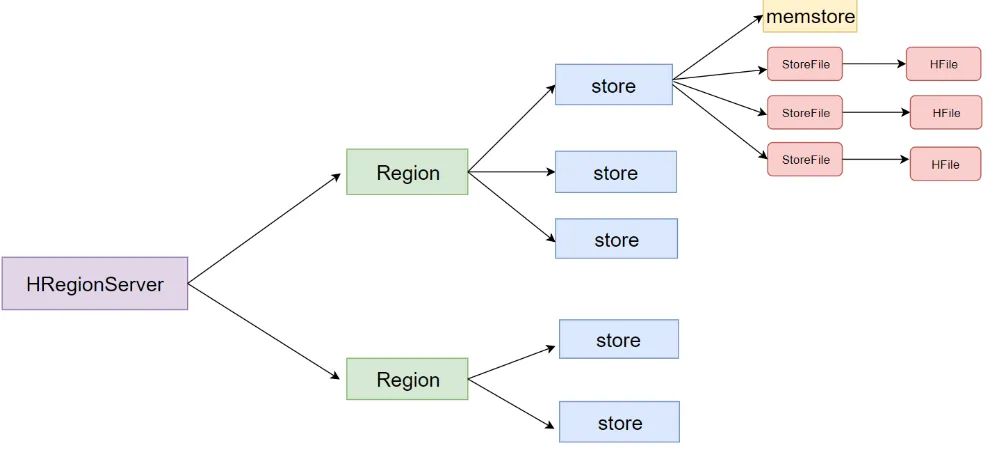
如上图所示,Hbase一张表由一个或多个Region组成,一个ReginServer可以存储一或多个Region,一个Region只能由一个机器存储。记录之间按照Row Key的字典序排列。Region按大小分割的,每个表一开始只有一个Region,随着数据不断插 入表,Region不断增大,当增大到一个阀值的时候,Region就会等分会 两个新的Hregion。当table中的行不断增多,就会有越来越多的 Region。
四. Hbase架构
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下:
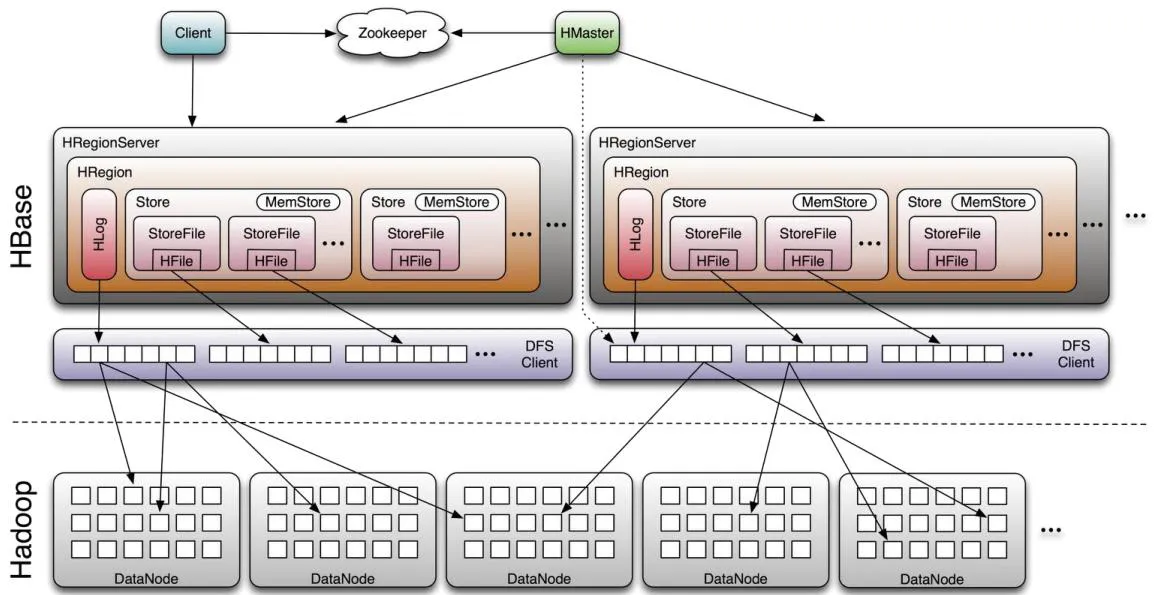
1、Client
提供了访问HBase的一系列API接口,如Java Native API、Rest风格http API、Thrift API、scala等,并维护cache来加快对HBase的访问。
2、Zookeeper
(1)保证任何时候,集群中只有一个master
(2)存贮所有Region的寻址入口。
(3)实时监控Region server的上线和下线信息,并实时通知Master
(4)存储HBase的schema和table元数据
3、Master
(1)为Region server分配region
(2)负责Region server的负载均衡
(3)发现失效的RegionServer并重新分配其上的region
(4)管理用户对table的增删改操作
4、RegionServer
Region server维护region,处理对这些region的IO请求,向HDFS文件系统中读写数据。一个RegionServer由多个region组成,一个region由多个store组成,一个store对应一个CF(列族),而一个store包括位于内存中的memstore和位于磁盘的storefile,每个storefile以HFile格式保存在HDFS上。写操作先写入memstore,当memstore中的数据达到某个阈值时,RegionServer会启动flashcache进程写入storefile,每次写入形成单独的一个storefile。
五.HBase RowKey设计
rowkey是一个二进制码流,可以是任意字符串,最大长度64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。建议越短越好,不要超过16个字节,原因如下:
- 数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
- MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
- 目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
rowkey散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
热点问题
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
下面是一些常见的避免热点的方法以及它们的优缺点:
加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题。
hbase的rowkey设计决定了数据的分区和查询的方式,是使用hbase前一定要想清楚的,以下简单列举了设计hbase rowkey时需要考虑的问题
1. rowkey是唯一的吗?
rowkey相同的记录在hbase里被认为是同一条数据的多个版本,查询时默认返回最新版本的数据,所以通常rowkey都需要保证唯一,除非用到多版本特性
最佳设计实践:
1 | rowkey就好比数据库的里的主键,他唯一确定了一条记录,它可以是一个字段也可以是多个字段拼接起来: |
2. 满足查询场景吗?
rowkey的设计限制了数据的查询方式,hbase只有两种查询方式:
- 根据完整的rowkey查询(get)
类似传统DB的sql:
select * from table where rowkey = ‘abcde’
这种查询方式需要知道完整的rowkey,即组成rowkey的所有字段的值都是确定的 - 根据rowkey的范围查询(scan):
类似传统DB的sql:
select * from table where ‘abc’ < rowkey <’abcx’
这种查询方式需要知道数据rowkey左边的值,就好像一本英文字典,你可以查询pre开头的所有单词,也可以查询prefi开头的所有单词,但是没办法查询中间是efi或结尾是ix的所有单词,除非翻阅整个字典。
最佳设计实践:
在有限的查询方式下如何实现复杂查询:
1 | 1.再建另外一张表作为索引表,应用双写 |
3. 数据足够分散,会产生热点吗?
散列的目的是数据可以分散到不同的分区,不至于产生热点,把某一台服务器累死,其他服务器闲置,充分发挥分布式和并发的优势
最佳设计实践:
1 | 1.md5 |
4. rowkey可以再短点吗?
短的rowkey可以减少数据量 ,提高查询写入性能
最佳设计实践:
1 | 1. 使用long或int型代替String |
5. scan时会不会查询出不需要的数据?
假设有以下场景:
table1的rowkey是: colume1+ colume2+ colume3
现在需要查询colume1= host1 的所有数据:
scan ‘table1’,{startkey=> ‘host1’,endkey=> ‘host2’}
此时如果有一条记录colume1=host12,这条记录也会被查询出来:因为:
‘host1’ < ‘host12’ < ‘host2’
但显然这条记录不是我们想要的
最佳设计实践:
1 | 1. 字段定长 |
常见设计实例:
日志类、时间序列数据
查询场景:
1.查询某台机器某个指标某段时间内的数据
[hostname][log-event][timestamp]
2.查询某台机器某个指标最新的几条数据
timestamp = Long.MAX_VALUE – timestamp
[hostname][log-event][timestamp]
3.数据只有时间一个维度或某一个维度数据量特别大
long bucket = timestamp % numBuckets;
[bucket][timestamp][hostname][log-event]
交易类数据
查询场景:
1.查询某个卖家某段时间内的交易记录
[seller id][timestmap][order number]
2.查询某个买家某段时间内的交易记录
[buyer id][timestmap][order number]
3.根据订单号查询
[order number]
4.同时满足1,2,3
三张表:
一张买家维度表,rowkey为:
[buyer id][timestmap][order number]
一张卖家维度表,rowkey为:
[seller id][timestmap][order number]
一张订单索引表,rowkey为:
[order number]